








Ausgezeichnet als
NEWSLETTER ABONNIEREN
Sie interessieren sich für die Projekte und Ergebnisse unserer Zukunftslabore? Unser Newsletter fasst die wichtigsten Ereignisse alle zwei Monate zusammen.
Jetzt anmeldenKünstliche Intelligenz (KI) ist fester Bestandteil des Alltags vieler Menschen. Sprachassistenten wie Siri oder Alexa beantworten Fragen, Navigations-Apps optimieren Reiserouten in Echtzeit und Streaming-Dienste schlagen passende Filme oder Musik vor. Chatbots wie ChatGPT unterstützen bei der Erstellung von Texten, während Bild-KI wie DALL·E kreative Grafiken generiert. Auch im Online-Shopping personalisieren Algorithmen Produktempfehlungen und in der Fotobearbeitung verbessern oder verändern KI-gestützte Tools Bilder mit wenigen Klicks. Doch mit der wachsenden Verbreitung steigt auch die Gefahr gezielter Angriffe, die Entscheidungen manipulieren oder Systeme für unerwünschte Zwecke nutzen.
Die Wissenschaftler*innen des Zukunftslabors Gesellschaft & Arbeit erforschen komplexe Angriffe auf KI-Systeme. In einer Studie nutzten sie drei verschiedene Algorithmen, die gezielt Bilder verfälschten, um KI-Modelle in die Irre zu führen. Die Algorithmen SemAdv, cAdV und NCF wurden von anderen Forscher*innen entwickelt, um die Anfälligkeit von KI-Modellen für gezielte Angriffe zu verdeutlichen. Die drei Algorithmen unterscheiden sich in ihrer Komplexität. Das bedeutet, dass sie in mehreren Iterationen Änderungen am Bild durchführen. Je mehr Iterationen das sind, desto komplexer wird der Angriff.
Angriffe auf KI machen deutlich, dass Künstliche Intelligenz keine unfehlbare Instanz ist. Deshalb ist es entscheidend, ihre Schwachstellen zu erforschen – und gleichzeitig sicherzustellen, dass Menschen die finale Entscheidung treffen und KI-Ergebnisse kritisch hinterfragen. Die Forschung zu Unrestricted Adversarial Examples hilft, Systeme robuster zu machen, aber auch das Bewusstsein dafür zu schärfen, dass der Mensch in der Verantwortung bleibt.

Adversarial Examples sind Eingaben (z. B. Bilder), die absichtlich manipuliert werden, um ein KI-Modell zu täuschen, sodass es falsche Vorhersagen trifft. Die Manipulationen sind restriktiv und oft minimal: Das ursprüngliche Bild wird leicht verändert (z.B. durch das Hinzufügen kleiner Pixelstörungen), sodass der Mensch den Unterschied kaum bemerkt, das Modell jedoch zu einer falschen Entscheidung veranlasst wird.
Unrestricted Adversarial Examples sind eine spezielle Klasse von Adversarial Examples. "Unrestricted" bedeutet hier, dass Veränderungen uneingeschränkt möglich sind. Sie sind in beliebiger Form manipulierte Eingaben, die gezielt erstellt werden, um das Modell zu täuschen. Technisch sind diese Angriffe also deutlich komplexer. Unrestricted Adversarial Examples zeigen, dass Modelle nicht nur durch minimale Veränderungen, sondern auch durch völlig neue oder stark veränderte Eingaben angreifbar sind.
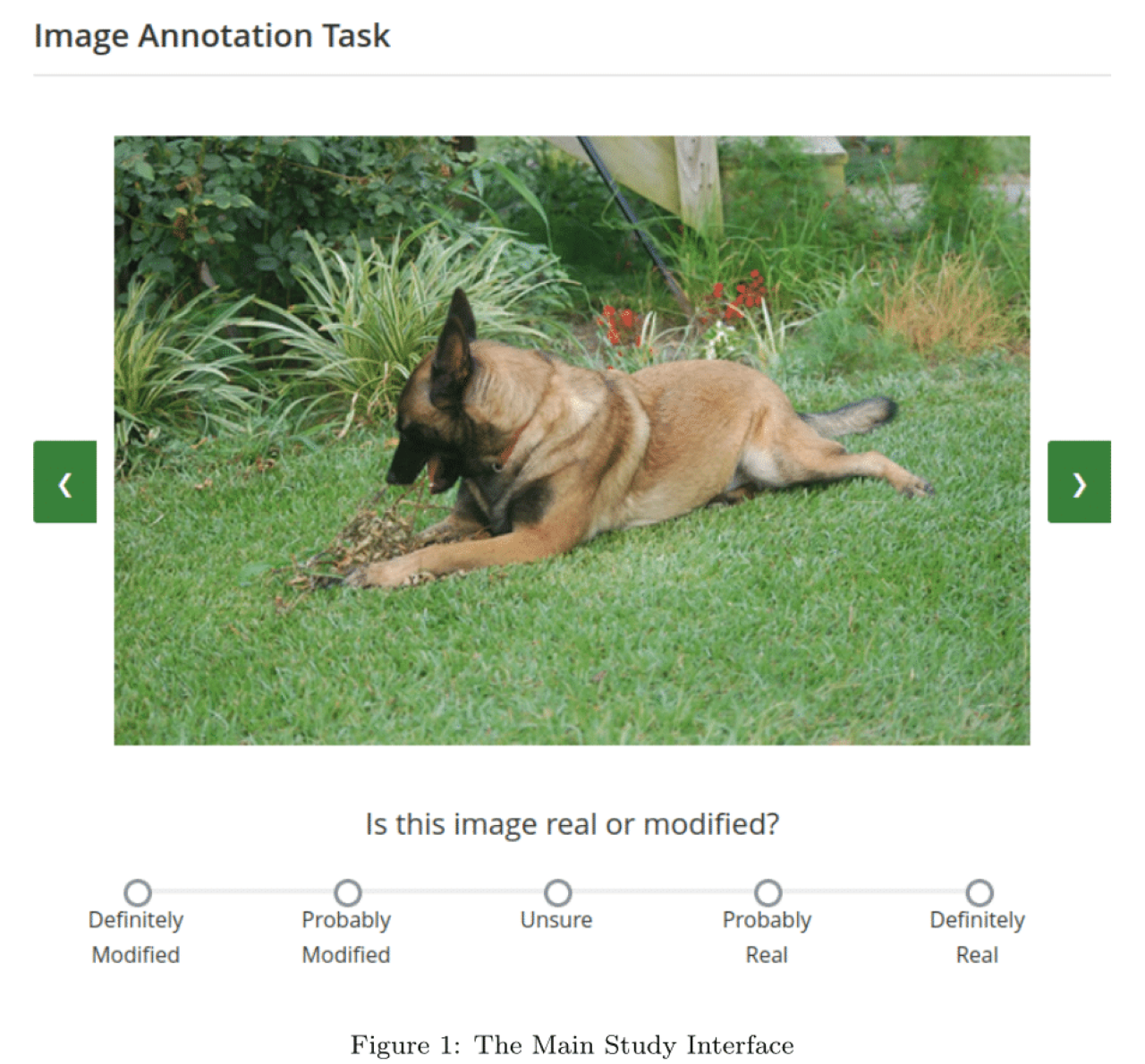
Ziel der Studie war es herauszufinden, ob Menschen die komplexen Angriffe (Unrestricted Adversarial Examples) auf KI-Modelle erkennen. Bisherige Studien hatten vor allem mathematische Metriken genutzt, um die Echtheit von Bildern zu prüfen. In der Studie des Zukunftslabors lag der Fokus auf der menschlichen Wahrnehmung.
Aufbau der Studie
Um die Studie möglichst robust – also zuverlässig und belastbar – zu gestalten, entwickelten die Wissenschaftler*innen das Konzept SCOOTER (Systemizing Confusion Over Observations To Evaluate Realness). Es ermöglicht, statistisch signifikante Meinungsbilder von Menschen zur Analyse von Unrestricted Adversarial Examples zu sammeln.
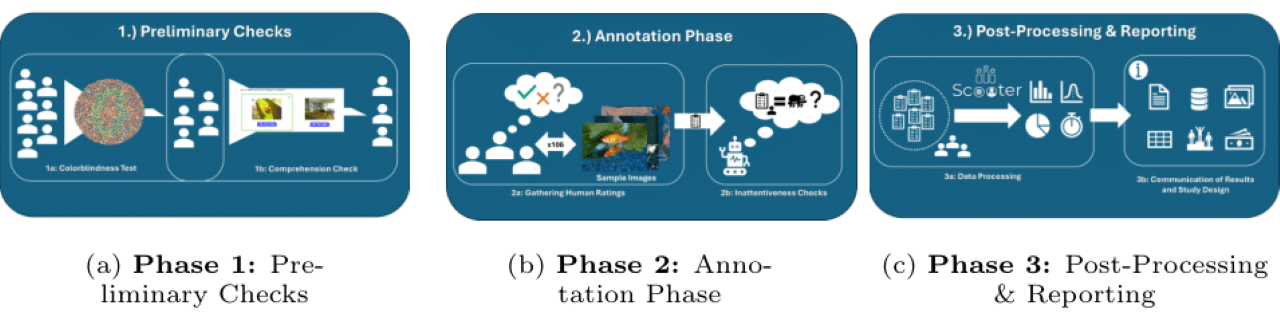
In der ersten Phase durchliefen die Proband*innen zwei Tests, um ihre Eignung für die Studienteilnahme festzustellen. Der erste Test diente dem Ausschluss einer Farbenblindheit, da für die Erkennung verfälschter Bilder auch farbliche Veränderungen wichtig sind. Im zweiten Test ging es um das Verständnis der englischen Sprache, weil die Studie auf Englisch durchgeführt wurde. Hatten die Proband*innen diese Vorabprüfungen bestanden, gelangten sie zur zweiten Phase – der Hauptstudie. Darin wurden ihnen insgesamt 106 Bilder gezeigt. 50 davon waren unverändert, weitere 50 waren durch die drei Angriffsalgorithmen (SemAdv, Cadv, NCF) farblich verfälscht. Sechs Bilder dienten dazu, die Aufmerksamkeit der Proband*innen sicherzustellen. Anhand einer Fünf-Punkte-Skala bewerteten die Proband*innen, wie sicher sie den Grad der Veränderung einschätzen. In der dritten Phase werteten die Wissenschaftler*innen die Ergebnisse aus und erstellten Statistiken zur menschlichen Wahrnehmung der Angriffe.
Zur Akquise der Proband*innen nutzten die Wissenschaftler*innen die Online-Plattform Prolific, die speziell für die Rekrutierung von Teilnehmer*innen für wissenschaftliche Studien entwickelt wurde. Die Wissenschaftler*innen führten die Studie mit einem iterativen Ansatz durch: Zunächst luden sie 25 Proband*innen dazu ein, die Bilder zu bewerten. Anschließend prüften die Wissenschaftler*innen, ob die Ergebnisse der 25 Proband*innen aussagekräftig genug waren. Sie entschieden, dass die Datengrundlage noch verbessert werden sollte, und akquirierten weitere 35 Proband*innen. So wurden die 106 Bilder von insgesamt 60 Proband*innen bewertet. Diese Datenbasis reichte aus, um belastbare Schlussfolgerungen ziehen zu können.
Ergebnis der Studie
Die Studie zeigte, dass Bilder, die durch die drei Angriffsalgorithmen verfälscht wurden, von den Proband*innen deutlich als modifiziert/nicht richtig wahrgenommen wurden. Diesem Ergebnis steht gegenüber, dass komplexe Attacken technisch gesehen viel besser funktionieren als einfache Attacken, da sie die KI-Modelle deutlich stärker zu Fehlverhalten veranlassen. Menschen hingegen können die komplexen Attacken viel eindeutiger erkennen. Folgende Beispielbilder veranschaulichen dieses Ergebnis:

